Diffusion models have become the state of the art for generative modelling, outperforming GANs on quality of sampling and auto-regressive models at density estimation. Their main downside is the slow sampling time: it takes several hundred model evaluations to generate a single high quality sample, which is not feasible for most applications.
ICLR 2022 has witnessed a multitude of papers focusing on speeding up the inference of diffusion models. One promising approach has already been introduced in a previous paper pill. Here, we present a second technique, put forth in [Sal21P].
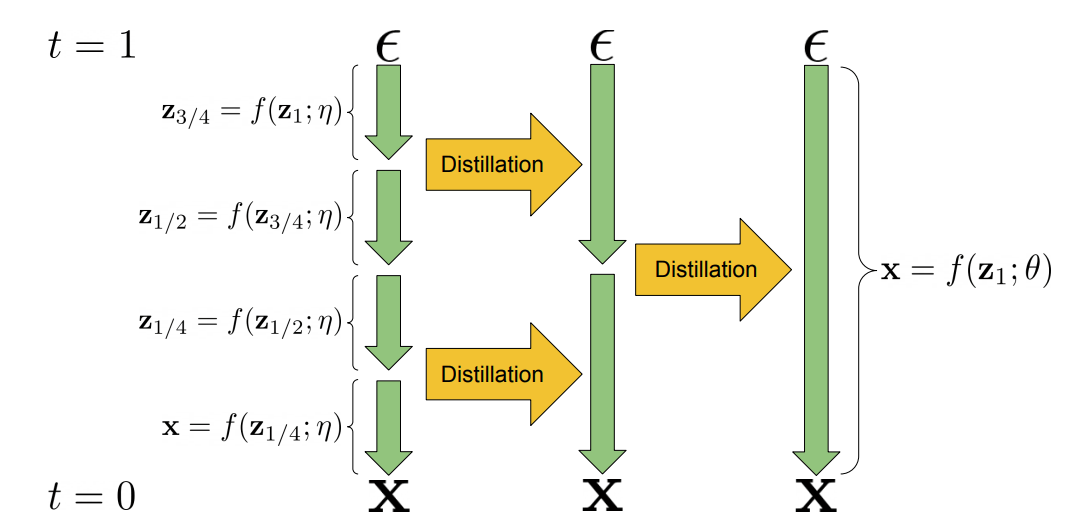
The main idea is rather simple: instead of creating new samples with the full diffusion model, one can iteratively halve the number of required sampling steps by distilling the slow “teacher” diffusion model into a faster student model. The student model is trained using as target the images created by the “teacher”, but skipping one step at a time, thus halving the required number of steps. This procedure can be repeated, using the student model as the new teacher, and training a new student model to halve the number of steps once again. By repeating this procedure it is possible to arrive at models taking as few as 10 steps for high quality samples, where the full model would need several hundreds.
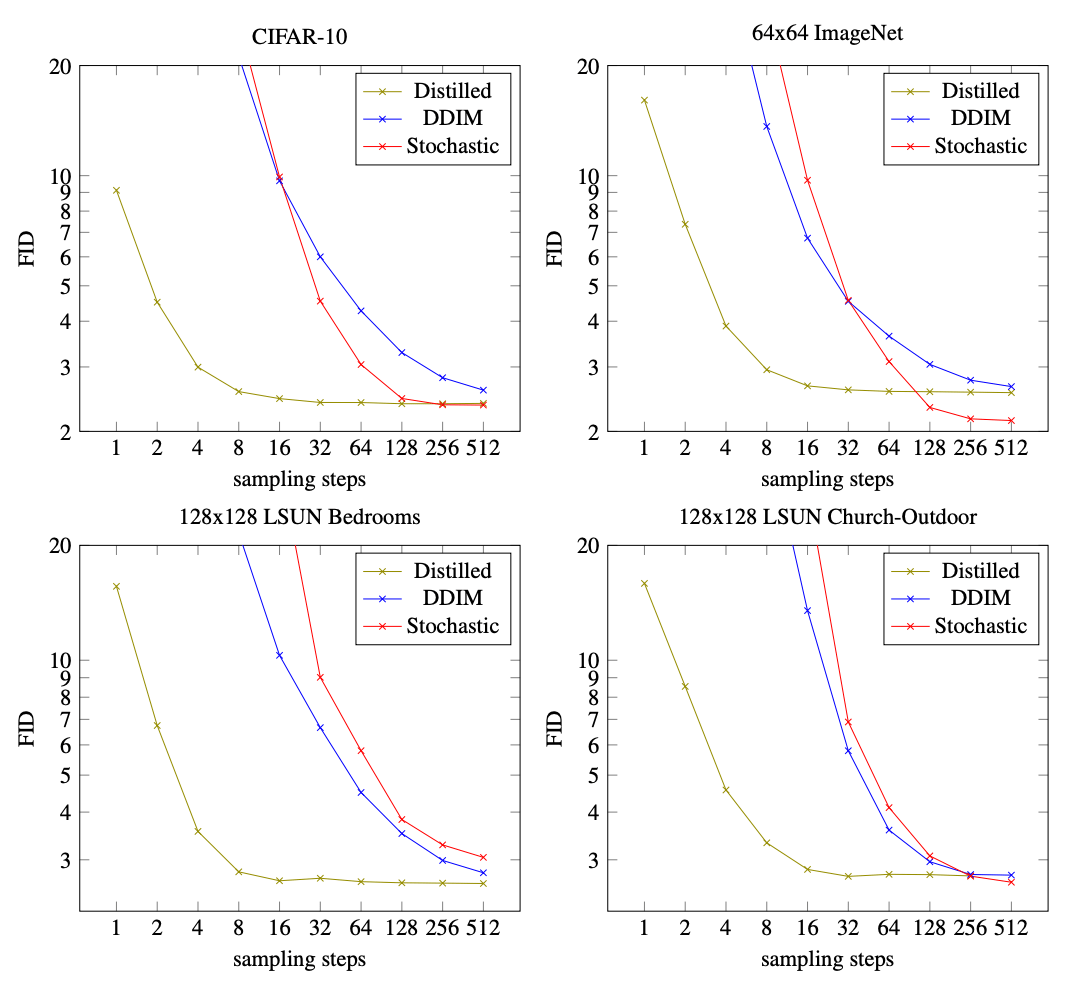
The image above compares the Frechet Inception Score (FID) of the distilled model to its teacher model (DDIM, originally introduced in the following paper “Denoising Diffusion Implicit Models” [Son22D] and to another optimised stochastic sampler for 4 different datasets. Introduced in [Heu18G], the FID score calculates the Wasserstein distance between the distribution of activations for generated and training images in one of the deeper layers of the Inception v3 network. The lower the score, the higher the quality of the generated images. The distilled model is able to achieve much higher sampling quality with lower number of sampling steps. Code and checkpoints are available on the group’s github page.
